Dataset:
For this case study, we have taken data from UCI Machine Learning Repository:
Liver Patients Data
The dataset consists of 583 rows and 11 attributes (including Target). However, there were 13 duplicate rows. We have removed the duplicate rows and left with 570 rows. Target 1 means the person is Liver patient and 2 means the person is not liver patient.
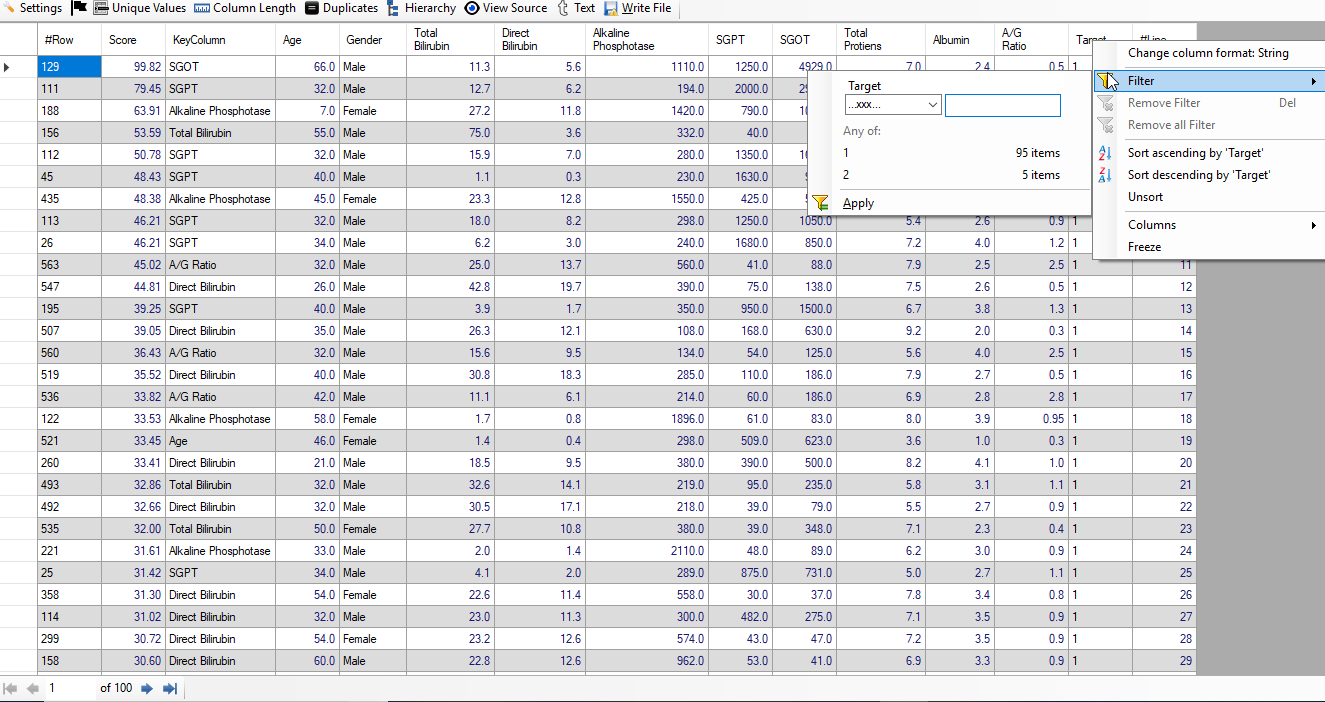
Result: Top 100 Liver Patients
We have selected the dataset in "Discover" and asked to find out top 100 liver patients. Below, we give the screenshot of "Discover":
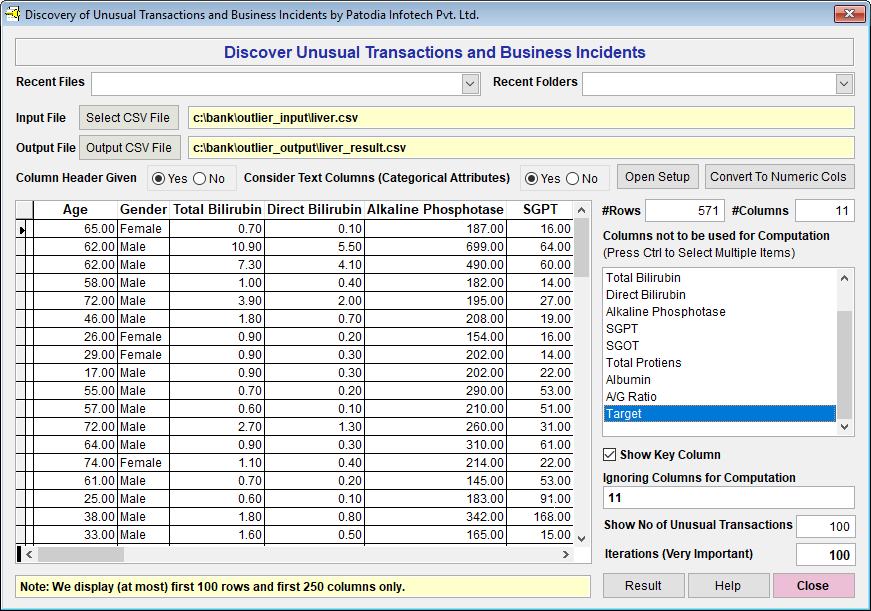
When we click on "Result" button, we see the following result (given screenshot of Result):
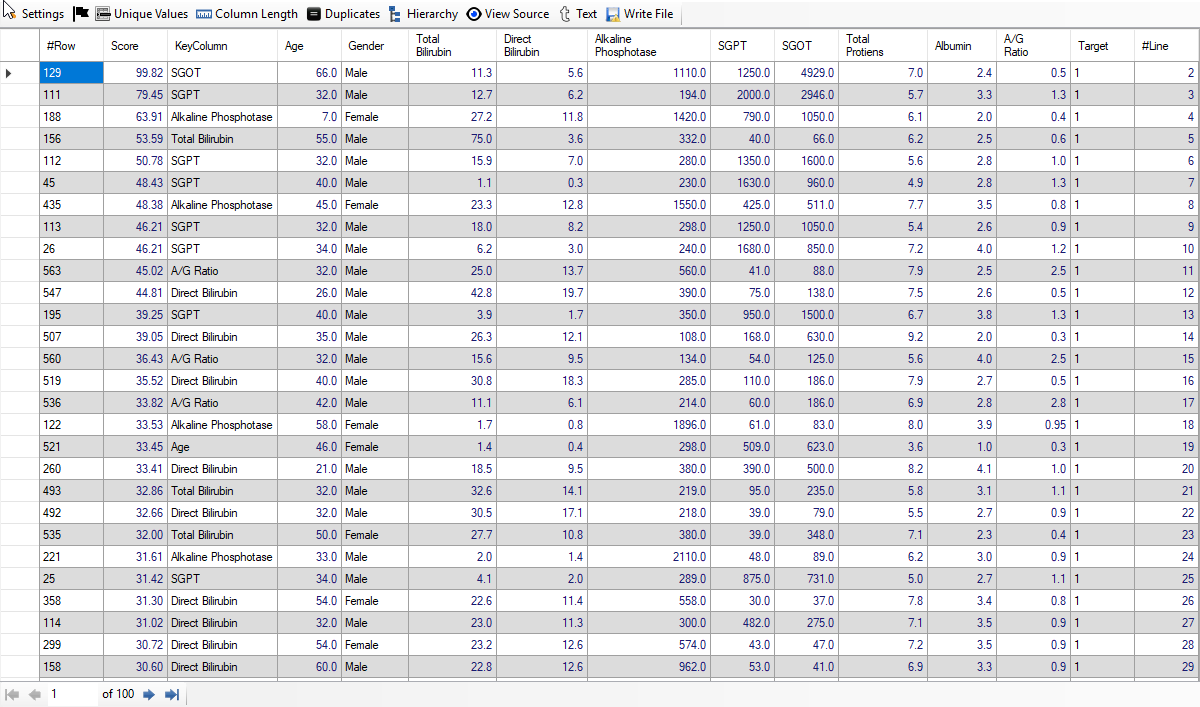
We find that out of 100 top rows; 95 rows are of Liver Patients. Thus, we have achieved accuracy of 95% from top 100 Liver data. It has been achieved without any feature engineering. Below, we give screenshot of the result: