Dataset:
For this case study, we have taken data from UCI Machine Learning Repository:
Epileptic Seizure Recognition Data
The dataset consists of 11500 rows and 180 columns. The data contains a recording of brain activity for 23.6 seconds for 500 persons. Each data point is the value of the EEG recording at a different point in time. So we have total 500 individuals with each has 4097 data points for 23.5 seconds. The data has been shuffled every 4097 data points into 23 chunks, each chunk contains 178 data points for 1 second, and each data point is the value of the EEG recording at a different point in time. So now we have 23 x 500 = 11500 pieces of information(row), each information contains 178 data points for 1 second(column), the last column represents the label y. The first column is ID.
The last column with the name 'y' can take value from 1 to 5. The meaning of each value is given below:
1 - Recording of seizure activity
2 - Recording of the EEG from the area where the tumor was located
3 - Yes they identify where the region of the tumor was in the brain and recording the EEG activity from the healthy brain area
4 - eyes closed, means when they were recording the EEG signal the patient had their eyes closed
5 - eyes open, means when they were recording the EEG signal of the brain the patient had their eyes open
Thus, if value of 'y' is 1, then the person has epileptic seizure. Other persons (having value of 'y' between 2 and 5) did not have epileptic seizure. There are 2,300 rows for each value of y resulting into total 11,500 rows.
Result: Top 1,000 Epileptic Seizure Recognition
We have selected the dataset in "Discover" and asked to find out top 1000 subjects had epileptic seizure. Below, we give the screenshot of "Discover":
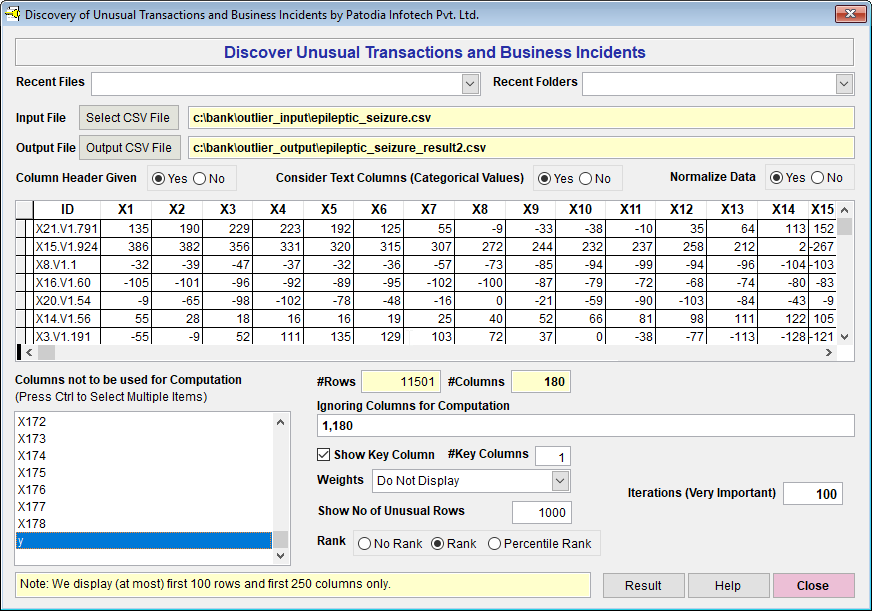
When we click on "Result" button, we see the following result (given screenshot of Result):
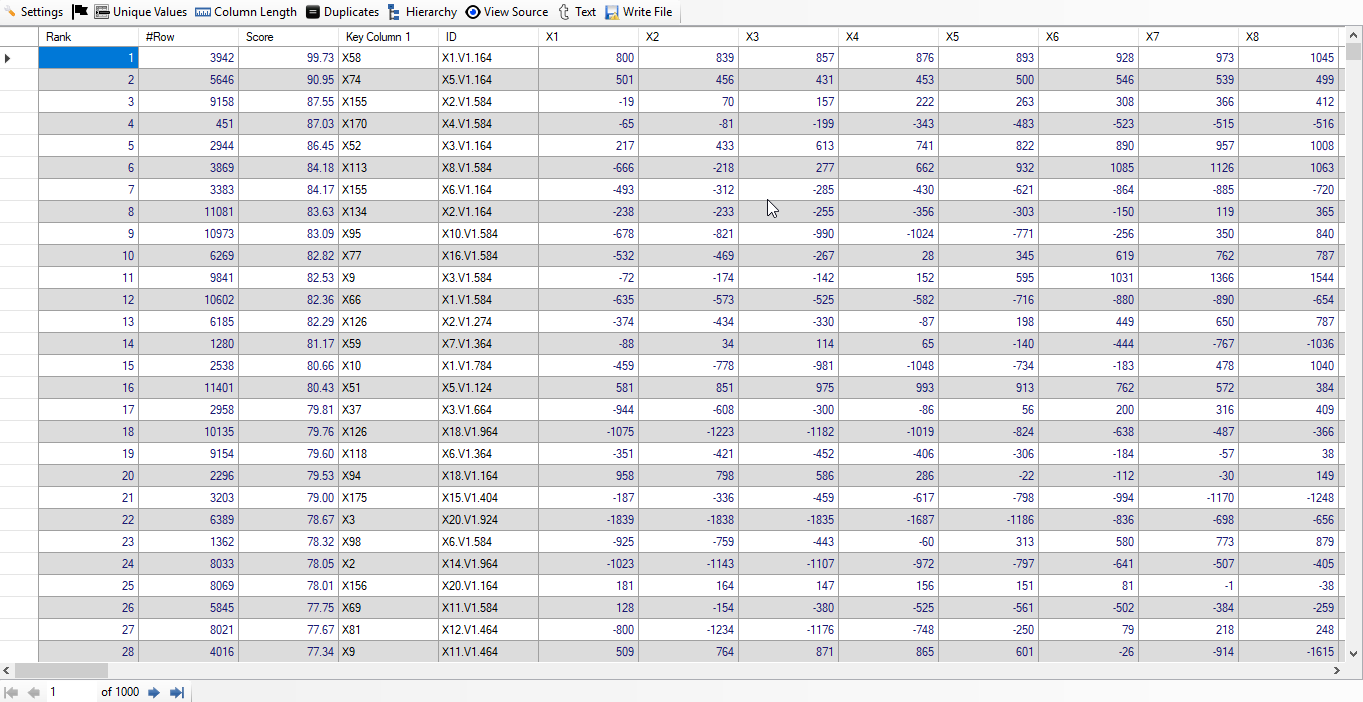
As we are able to see first few columns, so we have freezed first 5 columns and moved the cursor to last column, so that users can see the last few columns alongwith first few columns. The screenshot of the result is shown below:
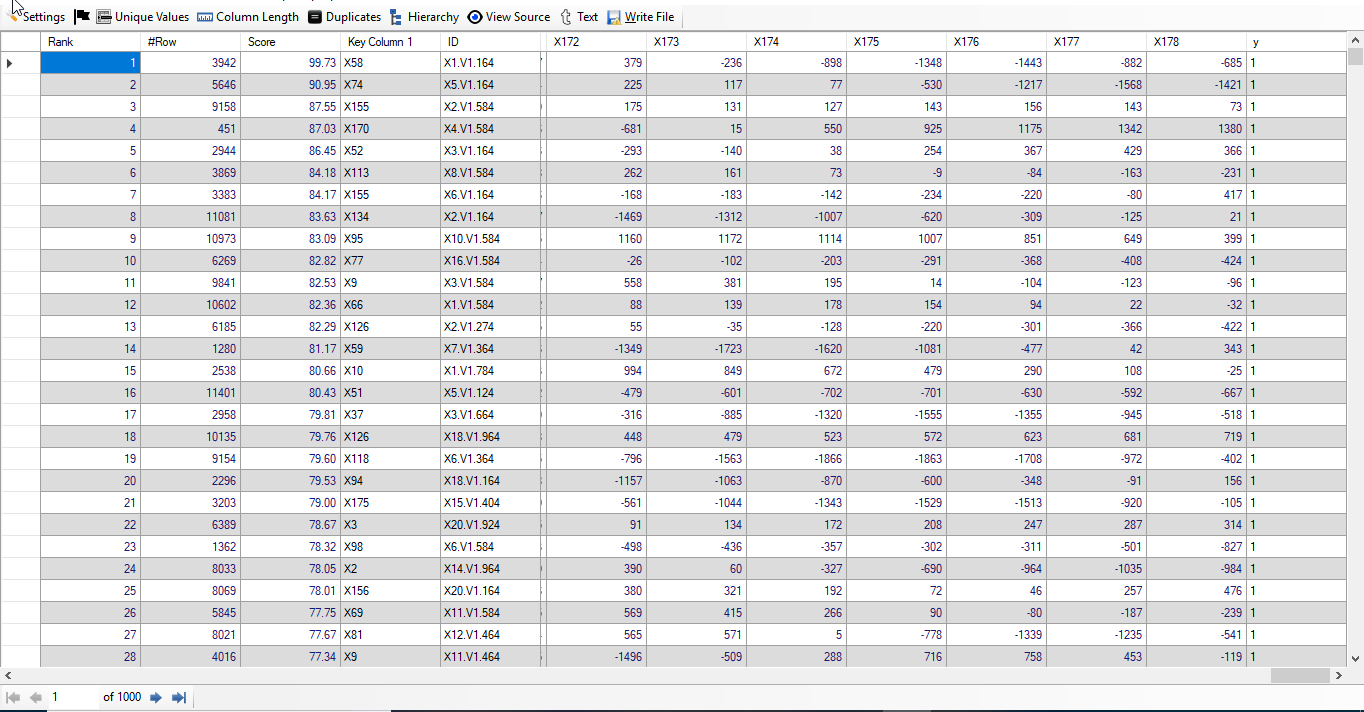
We find that out of 1,000 top rows, 973 rows are of the people who had epileptic seizure. Thus, we have achieved
accuracy of 97.3% from top 1,000 Epileptic Seizure Recognition data. It has been achieved without any feature engineering. Below, we give screenshot of the result:
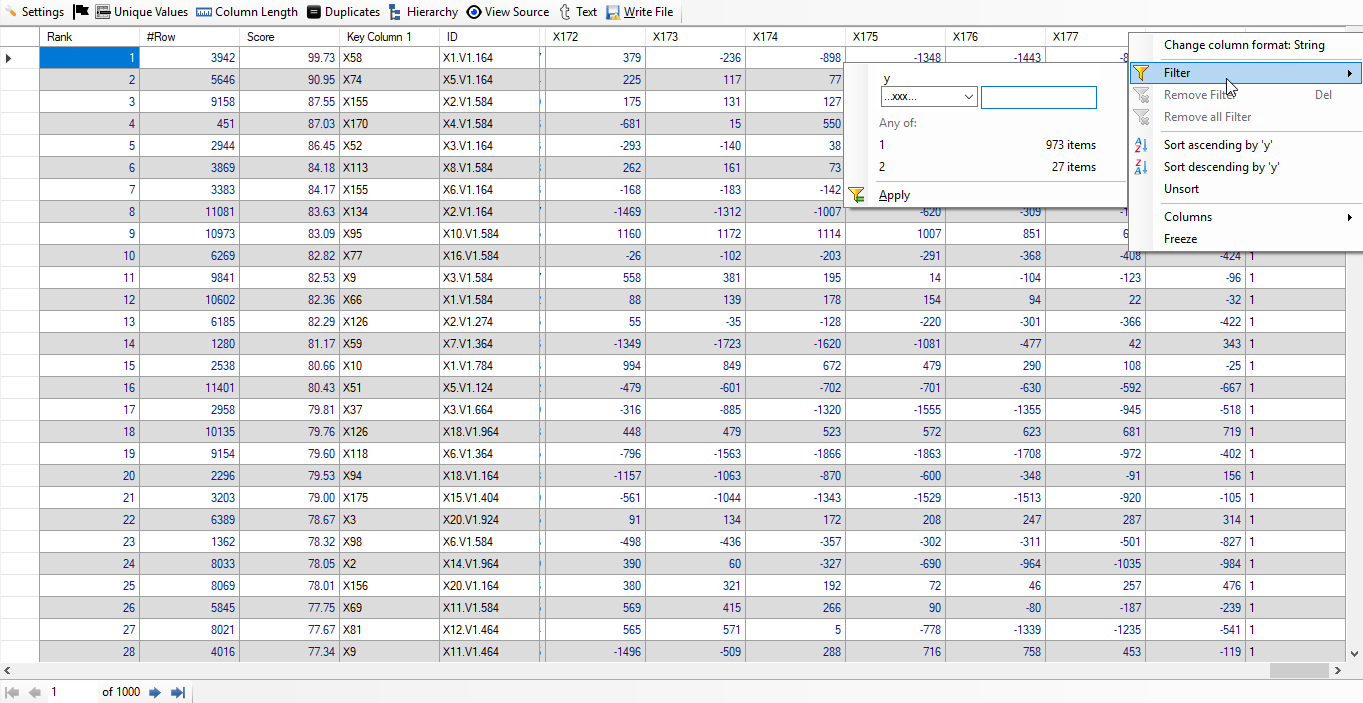
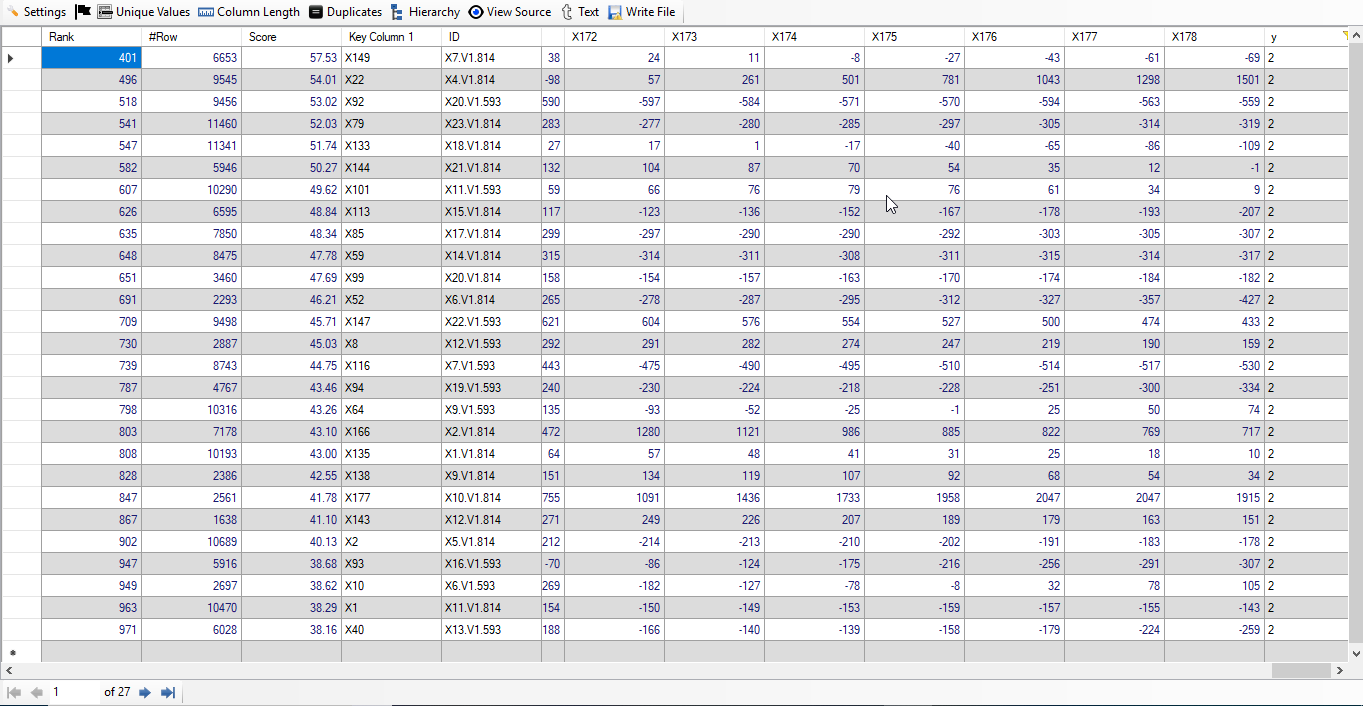
We just wanted to check the remaining 27 rows whose subjects did not have epileptic seizure. So, we have filtered for 'y' is equal to 2. Below, we give screenshot of the result:
 Note
Note: It is interesting to note that first false result has rank of 401. This means first 400 rows belong to the subjects who had epileptic seizure.
This is amazing result.
Time Taken: To process 11,500 rows with 178 columns with 100 iterations (Processed 2 million data 100 times) in 15 seconds on a moderate hardware and achieved accuracy of 97.3% without any feature engineering.
