Dataset:
For this case study, we have taken data of transactions made by credit cards in September 2013 by European Cardholders from Kaggle.com:
Credit Card Fraud Detection Data
The datasets contains transactions made by credit cards in September 2013 by European cardholders. This dataset contains transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
The data set comprises 31 columns. All columns are anonymized except 'Time', 'Amount' and 'Feature'. Apart from these 3 columns, there are 28 columns with the name 'V1', 'V2' to 'V28'. Features V1, V2, ... V28 are the principal components obtained with PCA.
The result is "Feature" (last column) representing whether the transaction is fraudulent or not. Feature 1 means Fraud and 0 means 'No Fraud'
Can we detect any type of fraud?
Yes, we can detect any type of fraud provided the required data are available. However, please note that we may have to feature engineering to improve the overall fraud detection rate.
Result: Top 1,000 Fraudulent Transactions
We have selected the dataset in "Discover" and asked to find out top 1,000 fraudulent transactions. Below, we give the screenshot of "Discover":
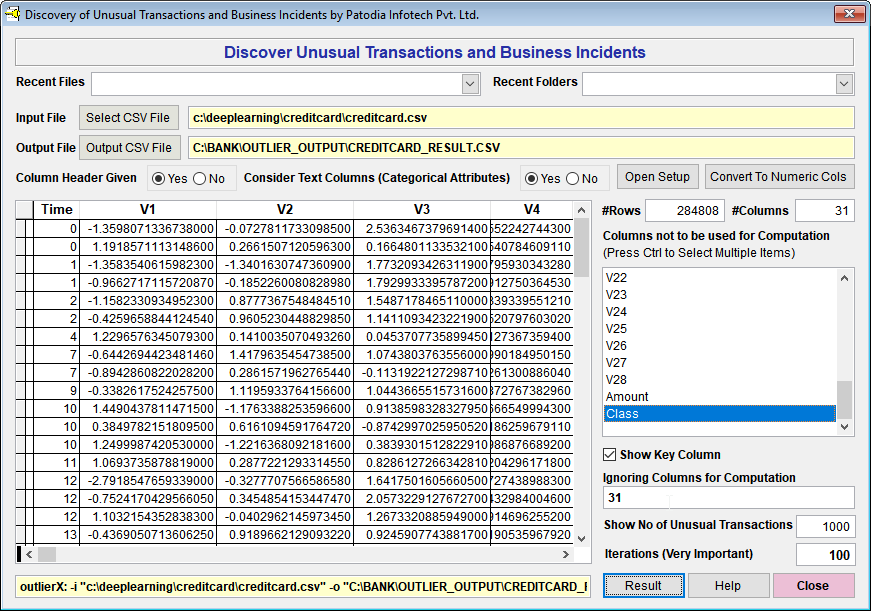
When we click on "Result" button, we see the following result (given screenshot of Result):
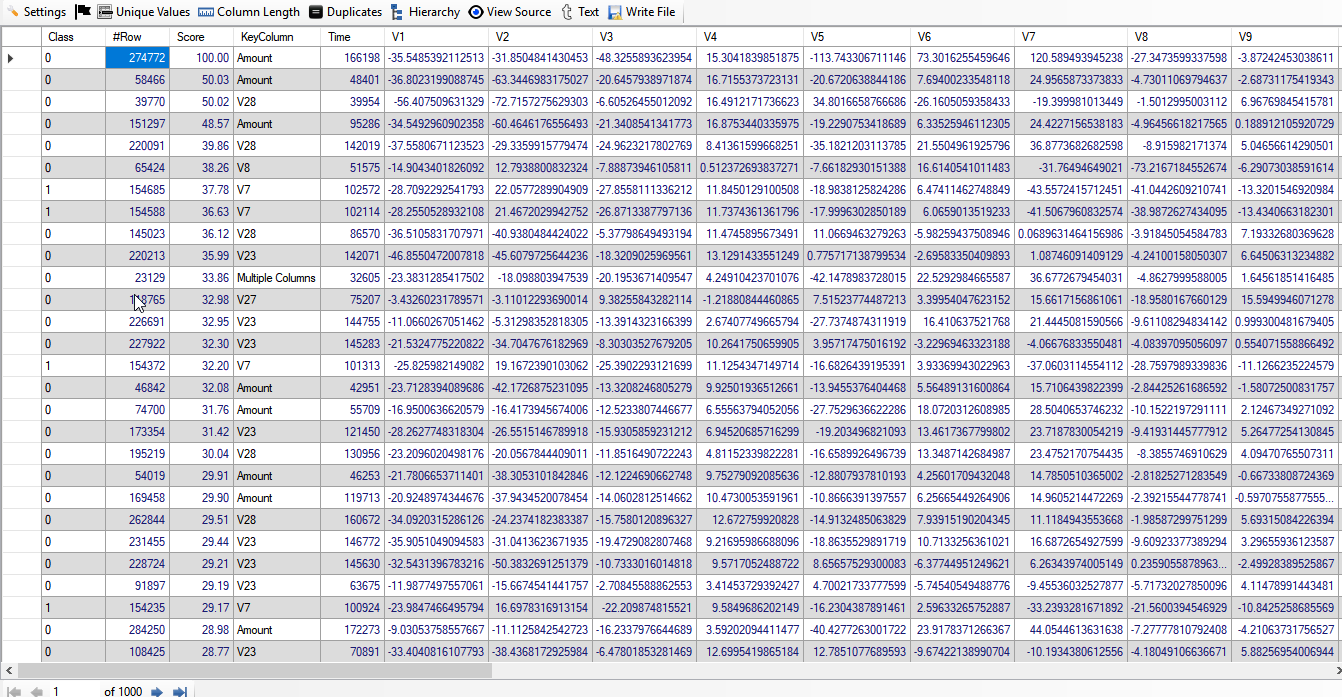
We find that out of 1,000 top rows; 182 rows are of Fraudulent transactions. Please note that there are 492 fraudulent transactions out of total 284,807 transactions. Thus, fraudulent transactions account for 0.172% of all transactions. If we take random 1,000 rows, we are expected to get 1.72 (or 2) rows containing fraudulent transactions. However, we got 182 rows (which is better than 100 times) of Fraudulent transactions without any feature engineering using "Discover". Below, we give screenshot of the result:
Result 2: Top 1,000 Fraudulent transactions
We got first result wherein we got 182 fraudulent transactions out of top 1,000 top transactions selected by "Discover". This was better than 100 times in comparison of random 1,000 rows. However, getting 182 out of total 492 fraudulent transactions means we have achieved accuracy of around 37% that is not good enough for banks.
To achieve, better result, we have done auto feature engineering facility provided by "Discover" and got the following result:
Below, we give feature and its value found by "Discover":
V17 = 32.3877
V14 = 11.1417
V12 = 8.9469
V16 = 3.0463
V3 = 0.172
We have taken top 4 features and created a new dataset with the features 'Time', V12, V14, V16, V17, Amount and Feature. We have ignored the column "V3" because its value is too small (below 1).
We have selected the dataset in "Discover" and asked to find out top 1,000 fraudulent transactions. Please note that we have not taken into account the columns 'Amount' and 'Feature'. Below, we give the screenshot of "Discover":
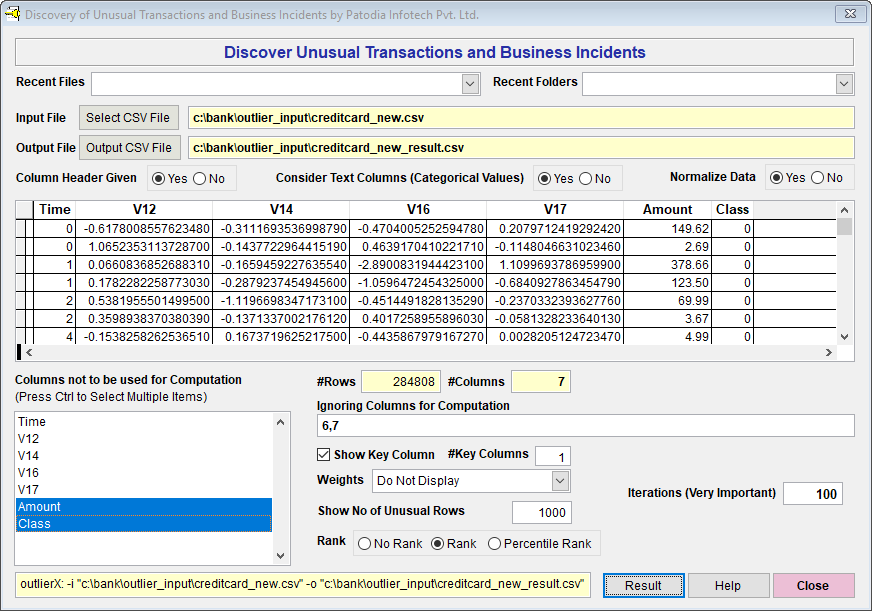
When we click on "Result" button, we see the following result (given screenshot of Result):
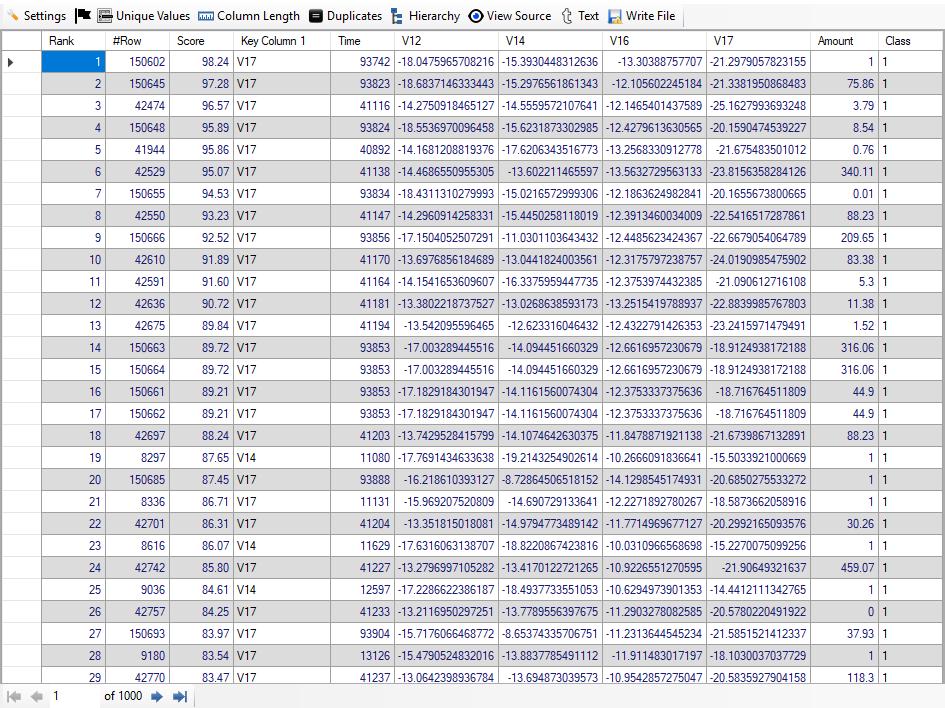
We find that out of 1,000 top rows; 407 rows are of Fraudulent transactions. Thus, we have achieved accuracy of 82.7% from top 1,000 transactions. It has been achieved using just 5 columns and auto feature engineering facility provided by "Discover". Below, we give screenshot of the result:
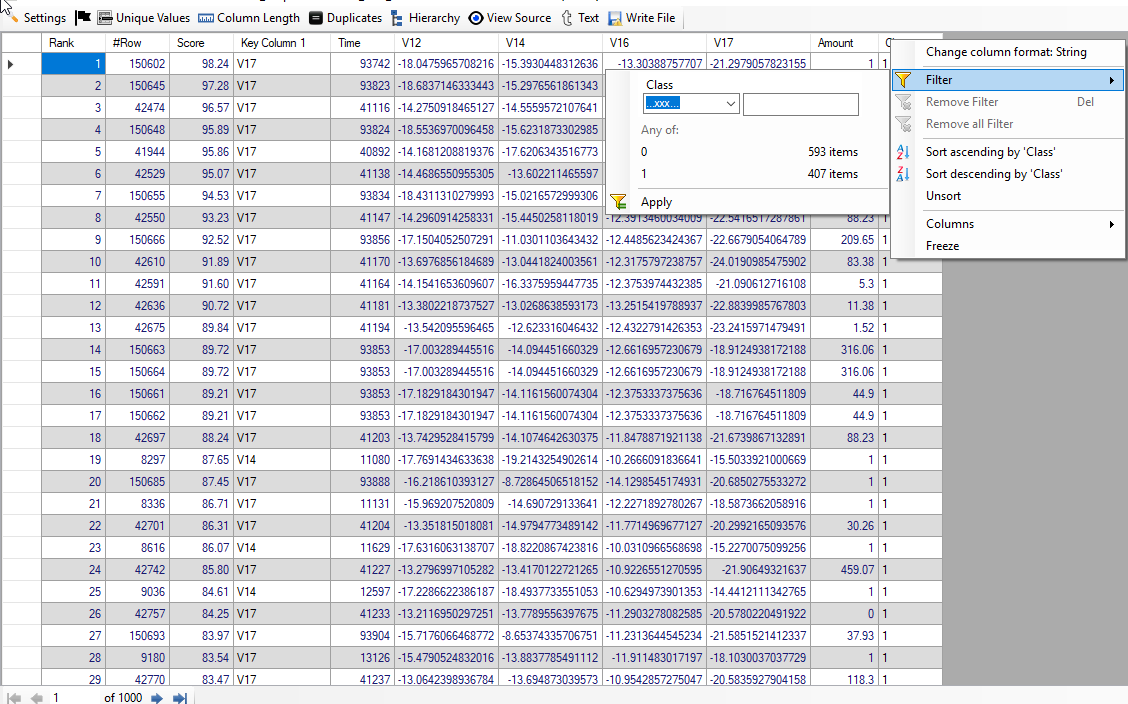 Non-Fraudulent Transactions
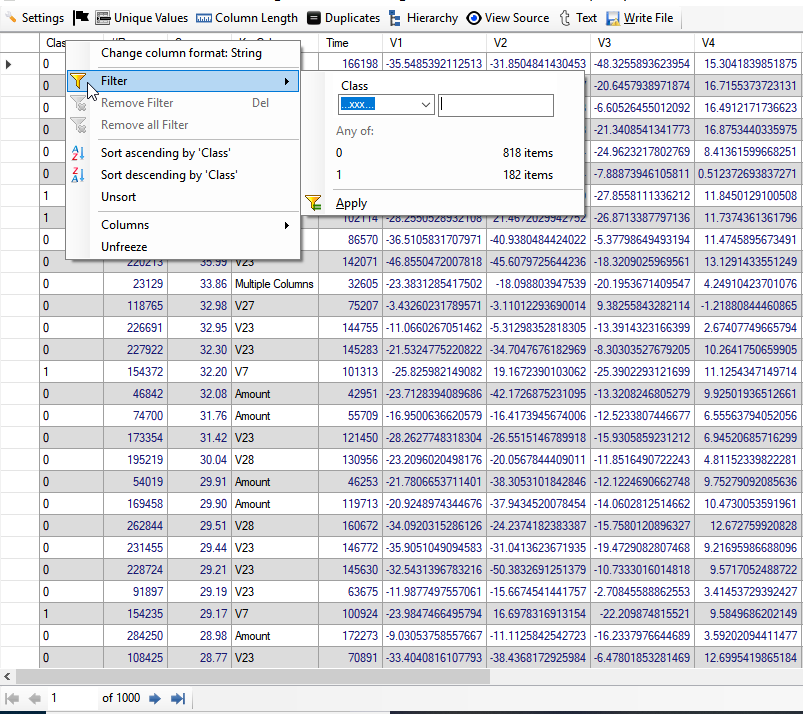
Non-Fraudulent Transactions: We have filtered all non-fraudulent transaction by putting class equal to 0. Below, we give screenshot of the result:
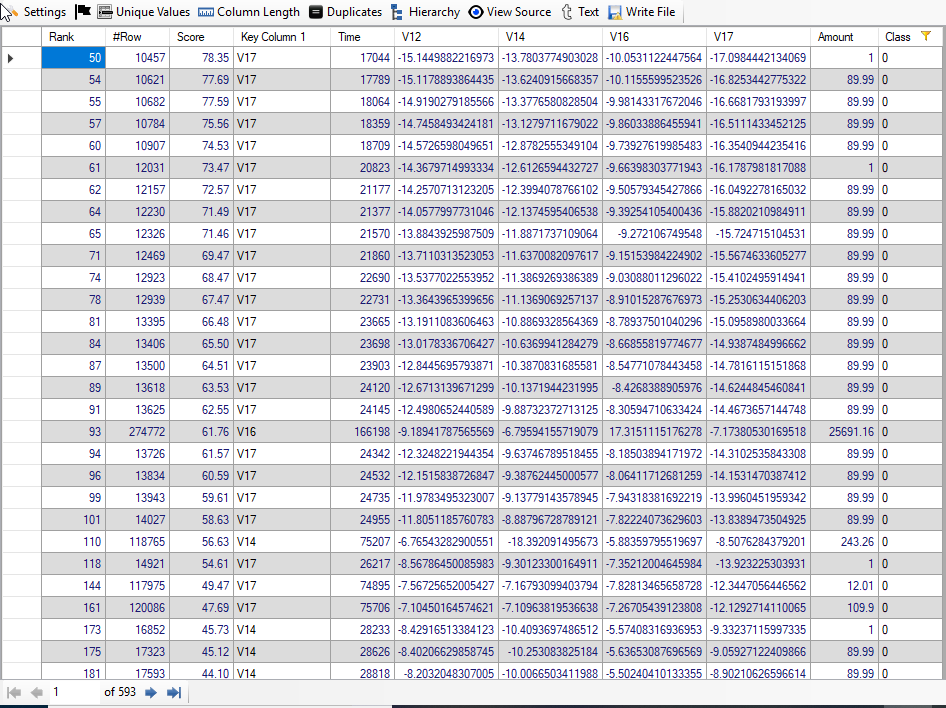
We see that first non-fraudulent transaction has rank of 50. Thus, top 49 transactions selected by "Discover" are really fraudulent transactions.
Time Taken: It hardly takes 4 to 5 seconds to get list of top 1,000 fraudulent transactions on a moderate hardware.
Top 50 Fraudulent transactions: If we check the top 50 transactions, we find that all are really fraudulent transactions. The first false positive transaction is 51st. Though, it might not be true always. However, we can expect that there will be very few false positive in top 50 or top 100 transactions.
Note: Please note that we prefer feature engineering using knowledge of domain expert. However, as most of the columns in the dataset were anonymized, we were forced to use feature engineering facility provided by "Discover". We expect to achieve accuracy of 90% and above based on feature engineering done using knowledge of domain expert.
Can we detect any type of fraud?
Yes, we can detect any type of fraud provided the required data are available. However, please note that we may have to do feature engineering to improve the overall fraud detection rate.
